So I’ve really gotten into julia over the past few days. Friday morning I sat down with trae-agent and zed and wrote a whole little agent. And now I’ve got the bug. It started with “I’m going to sit down and create my own programming language with MLIR because I can some weekend” and I never did it but I have been researching AD in modern programming languages including mojo and rust and other LLVM based languages that MLIR can differentiate with things like enzyme.
And I’m a roboticist so a python-like syntax that’s as fast as C is pretty much exactly what I’m looking for, what I set out to investigate/create with mojo and it’s like dude just learn julia. I found out about lux, which uses XLA and basically makes it to where you have the full power of jax/tensorflow at your fingertips in julia. You can even export to tensorflow flavored output files and let the python inference ecosystem take it from there.
Of course that’s now what we want to do is it class? Why else would we write up a tool calling example using openai endpoint in julia if we weren’t aiming for a full julia stack, including for inference?
So I’m investigating the structure of DSPy with a fine toothed comb. Perusing things so I have an idea of how to do a minimal example using like [GEPA][gepa] to create an optimal trae-agent and it’s all in julia before I try to port the whole functionality, because DSPy has a lot of functionality that I do actually want to port over but you know, priorities.
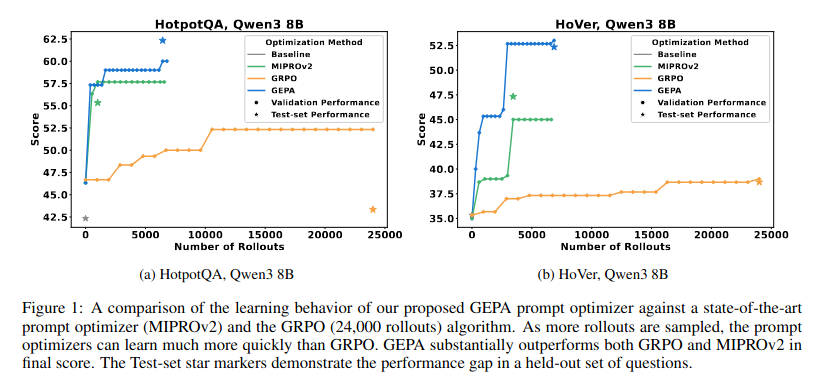
Pretty impressive
So yeah I want to create the bare bones for a DSPy like system in julia that does the whole tracing learning updating prompts that are attached to the signatures/modules.
You know what I should do? I should plug into qwen3:8b and have it read my whole codebase and explain what it’s doing. Just use ollama? Context length is a concern I guess. I need to download the qwen3:4b-thinking tbh. That’s what it’s good for. Reading long documents to get the idea. I can bump up context length in ollama. Yeah let’s do this. Okay I’m doing that in another window just letting zed chug along. It’s not so impressive with qwen3:8b compared to claude4_sonnet, and trae-agent with qwen3:8b is pretty limited.
Muon for Optimizers.jl¶
# NewtonSchulz5 implementation adapted from the journal entry
function newtonschulz5(G; steps=5, eps=1e-7)
a, b, c = 3.4445, -4.7750, 2.0315
X = G
normX = norm(X)
if normX == 0
return zero(G)
end
X = X / (normX + eps)
transpose = size(X, 1) > size(X, 2)
if transpose
X = X'
end
for _ in 1:steps
A = X * X'
B = b * A + c * (A * A)
X = a * X + B * X
end
if transpose
X = X'
end
return X
end
"""
Muon(η = 0.01, μ = 0.9)
Muon(; [eta, mu])
Muon optimizer with learning rate `η` and momentum `μ`.
The Muon optimizer uses orthogonalized momentum updates via Newton-Schulz iterations.
It maintains a momentum buffer that is orthogonalized before being used in parameter updates.
Note: This implementation returns η * O as the update term. The Optimisers.jl framework
will handle the actual parameter update θₙ = θₙ₋₁ - update.
# Parameters
- Learning rate (`η == eta`): Amount by which gradients are discounted before updating
the weights.
- Momentum (`μ == mu`): Controls the momentum term used in the optimizer.
"""
struct Muon{T} <: AbstractRule
eta::T
mu::T
end
Muon(η=0.01, μ=0.9) = Muon(promote(η, μ)...)
init(o::Muon, x::AbstractArray) = zero(x)
function apply!(o::Muon, state, x, dx)
η, μ = o.eta, o.mu
# Update momentum buffer: B_t = μ * B_{t-1} + G_t
B = μ * state + dx
# Compute orthogonalized update direction: O_t = NewtonSchulz5(B_t)
O = newtonschulz5(B)
# Return the update term η * O (the framework will handle θₙ = θₙ₋₁ - update)
dx′ = @lazy η * O
# Return updated momentum buffer and parameter update term
return B, dx′
end
function Base.show(io::IO, o::Muon)
print(io, "Muon(eta=$(o.eta), mu=$(o.mu))")
endNeed to test this out and make a PR to Optimizers.jl
Building Agents¶
This blog is fantastic. Deserves a full write up of what I think about each step and how I’ve encountered similar patterns.